CAREER: Welfare-Centric Machine Learning
This material is based upon work supported by the National Science Foundation under Grant IIS - 1942702 (Faculty Early Career Development Program). Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.
Project Description
Many decisions that once were made by humans are now made using algorithms. These algorithms are typically designed with a single, profit-related objective in mind: Loan approval algorithms are designed to maximize profit, smart phone apps are optimized for engagement, and news feeds are optimized for clicks. However, these decisions have side effects: irresponsible payday loans, addictive apps, and fake news can harm individuals and society.
This project will develop and test a new paradigm for prioritizing the social impact of an algorithmic decision from the start, rather than as an afterthought. The key insight is to leverage recent advances in machine learning -- which make it possible to predict who will benefit from a decision and how -- to design algorithms that balance those predicted benefits alongside traditional profit-related objectives. The research goals of the award are complemented by an educational plan to develop new curricula at the intersection of welfare economics and fair machine learning. The award will also support a series of workshops to educate policymakers and practitioners on how to use machine learning in a way that prioritizes the well-being of society.
The technical aims of the project have three main thrusts. The first is to develop a theory of welfare-centric machine learning: a formal, quantitative framework for weighing the social welfare effects of an algorithm alongside traditional, private optimization criteria. This involves first defining a notion of social welfare, based on principles of welfare economics, and characterizing how welfare can be impacted by a decision algorithm. It then integrates recent advances in multi-objective machine learning to formally balance social welfare maximization with traditional loss minimization. The second thrust is to improve empirical methods for measuring social welfare from 'digital trace' data. Scalable methods for estimating welfare and welfare impacts are required if we want algorithms to maximize those impacts. The final thrust highlights the broad relevance of this framework by applying it to real-world data from three different decision-making contexts: (i) In consumer credit, it will show how welfare-sensitive credit scores can balance the need for profit maximization with the desire to make socially-responsible lending decisions. (ii) In content recommendation, it will demonstrate how content providers can jointly optimize for quality and engagement, and provide regulators with tools for estimating the 'social cost per click.' (iii) In the design of humanitarian aid programs, it will illustrate how welfare-centric algorithms can enable policymakers to effectively and transparently balance multiple social objectives.
Research papers
We study poverty minimization via direct transfers, framing this as a statistical learning problem while retaining the information constraints faced by real-world programs. Using nationally representative household consumption surveys from 23 countries that together account for 50% of the world’s poor, we estimate that reducing the poverty rate to 1% (from a baseline of 12% at the time of last survey) would cost $170B nominal per year. This is 5.5 times the corresponding reduction in the aggregate poverty gap, but only 19% of the cost of universal basic income. Extrapolated globally, the results correspond to a cost of (approximately) ending extreme poverty of roughly 0.3% of global GDP.
An increasing number of decisions are guided by machine learning algorithms. In many settings, from consumer credit to criminal justice, those decisions are made by applying an estimator to data on an individual's observed behavior. But when consequential decisions are encoded in rules, individuals may strategically alter their behavior to achieve desired outcomes. This paper develops a new class of estimator that is stable under manipulation, even when the decision rule is fully transparent. We explicitly model the costs of manipulating different behaviors, and identify decision rules that are stable in equilibrium. Through a large field experiment in Kenya, we show that decision rules estimated with our strategy-robust method outperform those based on standard supervised learning approaches.
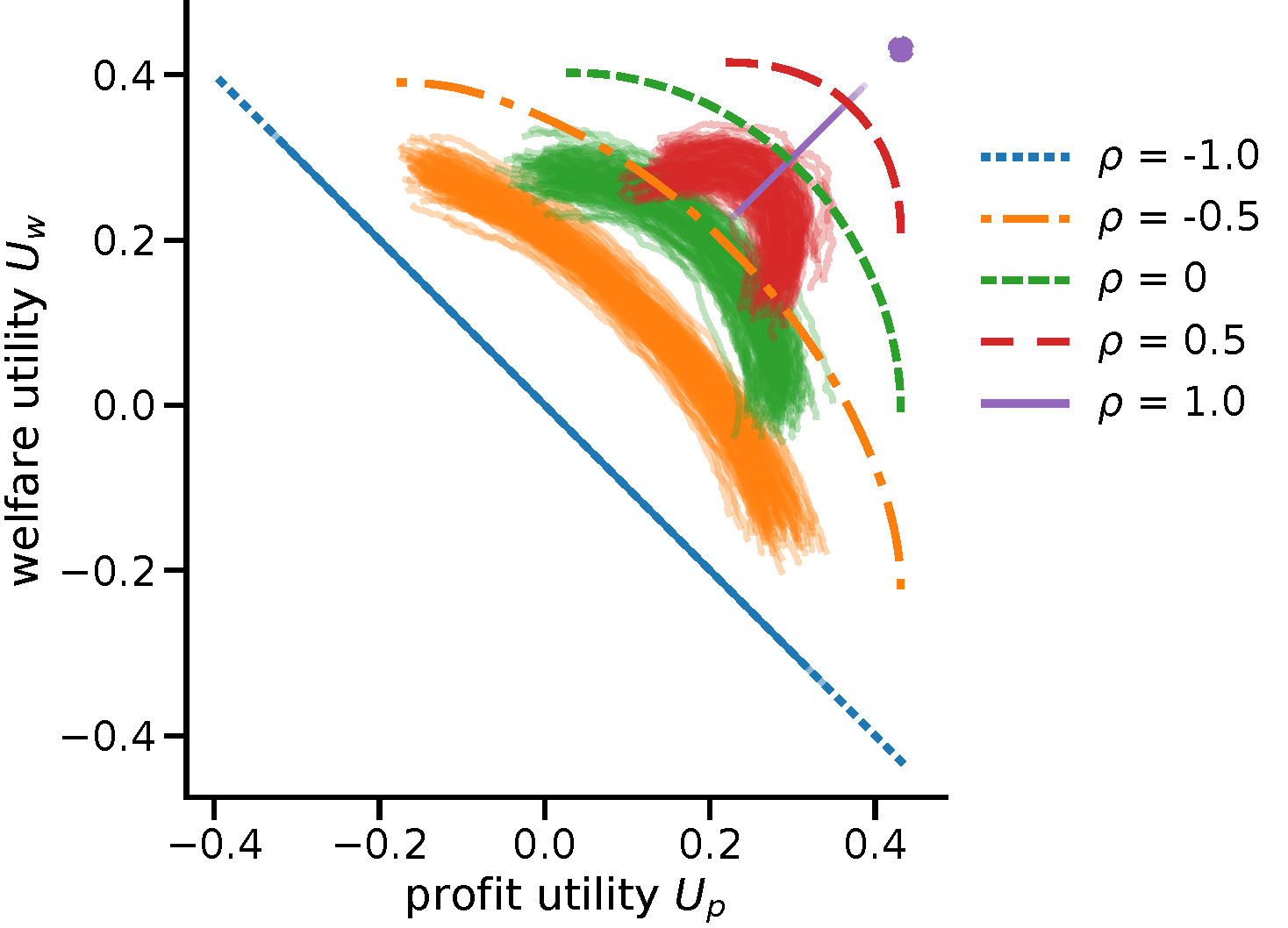
While real-world decisions involve many competing objectives, algorithmic decisions are often evaluated with a single objective function. In this paper, we study algorithmic policies which explicitly trade off between a private objective (such as profit) and a public objective (such as social welfare). We analyze a natural class of policies which trace an empirical Pareto frontier based on learned scores, and focus on how such decisions can be made in noisy or data-limited regimes. Our theoretical results characterize the optimal strategies in this class, bound the Pareto errors due to inaccuracies in the scores, and show an equivalence between optimal strategies and a rich class of fairness-constrained profit-maximizing policies. We then present empirical results in two different contexts --- online content recommendation and sustainable abalone fisheries --- to underscore the generality of our approach to a wide range of practical decisions. Taken together, these results shed light on inherent trade-offs in using machine learning for decisions that impact social welfare.
When a policy prioritizes one person over another, is it because they benefit more, or because they are preferred? This paper develops a method to uncover the values consistent with observed allocation decisions. We estimate how much each individual benefits from an intervention, and then reconcile the allocation with (i) the welfare weights assigned to different people; (ii) heterogeneous treatment effects of the intervention; and (iii) weights on different outcomes. We demonstrate this approach by analyzing Mexico's PROGRESA anti-poverty program. The analysis reveals that while the program prioritized certain subgroups - such as indigenous households - the fact that those groups benefited more implies that the program did not actually assign them a higher welfare weight. We also find evidence that the policy valued outcomes differently from households. The PROGRESA case illustrates how the method makes it possible to audit existing policies, and to design future policies that better align with values.