Basic Information
| Position: | Chancellor's Professor, School of Information and Public Policy Director, Global Opportunity Lab Faculty Co-Director, Center for Effective Global Action University of California, Berkeley |  |
| Contact: | jblumenstock[@]berkeley[.]edu | |
| My work is focused on the design, rigorous evaluation, and improvement of machine learning and artificial intelligence systems intended to address concrete policy problems facing poor and vulnerable populations. You can find a short professional bio here. | ||
Featured Publications
Björkegren, D, Blumenstock, JE, and Knight, S (2026). Manipulation-Robust Prediction, Accepted, American Economic Review [pdf]
An increasing number of decisions are guided by machine learning algorithms. But when consequential decisions are encoded in algorithms, individuals may strategically alter their behavior to achieve desired outcomes. This paper develops an empirical approach to adjust decision algorithms to anticipate manipulation. By explicitly modeling incentives to manipulate, our approach produces decision rules that are stable under manipulation, even when the rules are fully transparent. We stress test this approach through a large field experiment in Kenya. When implemented, decision rules estimated with this strategy-robust approach outperform those based on standard machine learning approaches.
Björkegren, D, Blumenstock, JE, and Knight, S (2025). What Do Policies Value?, Review of Economic Studies [pdf]
When a policy prioritizes one person over another, is it because they benefit more, or because they are preferred? This paper develops a method to uncover the values consistent with observed allocation decisions. We estimate how much each individual benefits from an intervention, and then reconcile the allocation with (i) the welfare weights assigned to different people; (ii) heterogeneous treatment effects of the intervention; and (iii) weights on different outcomes. Analyzing Mexico's PROGRESA anti-poverty program, we find that while the program prioritized certain subgroups - such as indigenous households - the fact that those groups benefited more implies that the program did not actually assign them a higher welfare weight. The PROGRESA case illustrates how the method makes it possible to audit existing policies, and to design future policies that better align with values.
Aiken, E, Bellue, S, Karlan, D, Udry, C, and Blumenstock, JE (2022). Machine Learning and Phone Data Can Improve the Targeting of Humanitarian Aid, Nature, 603: 864-870 [pdf]
Targeting is a central challenge in the administration of anti-poverty programs: given available data, how does one rapidly identify the individuals and families with the greatest need? Here we show that non-traditional “big” data from satellites and mobile phone networks can improve the targeting of anti-poverty programs. Our analysis compares outcomes – including exclusion errors, total social welfare, and measures of fairness – under different targeting regimes. Relative to other feasible targeting options, the machine learning approach reduces errors of exclusion by 4-21%. These results highlight the potential for new data sources to contribute to humanitarian response efforts, particularly in crisis settings when traditional data are missing or out of date.
Chi, G, Fang, S, and Blumenstock, JE (2022). Microestimates of Wealth and Poverty for all Low- and Middle-Income Countries, Proceedings of the National Academy of Sciences, 119(3), 1-11 [pdf]
Many critical policy decisions rely on data about the geographic distribution of wealth and poverty. Yet many poverty maps are out of date or exist only at very coarse levels of granularity. Here we develop the first microestimates of wealth and poverty that cover the populated surface of all 135 low and middle-income countries (LMICs) at 2.4km resolution. The estimates are built by applying machine learning algorithms to vast and heterogeneous data from satellites, mobile phone networks, topographic maps, as well as aggregated and de-identified connectivity data from Facebook. We train and calibrate the estimates using nationally-representative household survey data from 56 LMICs, then validate their accuracy using four independent sources of household survey data from 18 countries. We also provide confidence intervals for each microestimate to facilitate responsible downstream use...
Rolf, Simchowitz, Dean, Liu, Björkegren, Hardt, and Blumenstock (2020). Score-Based Classifiers for Welfare-Aware Machine Learning, International Conference on Machine Learning (ICML '20) [pdf]
While real-world decisions involve many competing objectives, algorithmic decisions are often evaluated with a single objective function. We study algorithmic policies which explicitly trade off between a private objective (such as profit) and a public objective (such as social welfare). We analyze a natural class of policies which trace an empirical Pareto frontier based on learned scores, and focus on how such decisions can be made in noisy or data-limited regimes. Our theoretical results characterize the optimal strategies in this class, bound the Pareto errors due to inaccuracies in the scores, and show an equivalence between optimal strategies and a rich class of fairness-constrained profit-maximizing policies.
View all publications...
Featured Ongoing Projects
What Would it Cost to End Extreme Poverty? - joint with Paul Niehaus, Roshni Sahoo, Leo Selker, Stefan Wager
We study poverty minimization via direct transfers, framing this as a statistical learning problem while retaining the information constraints faced by real-world programs. Using nationally representative household consumption surveys from 23 countries that together account for 50% of the world’s poor, we estimate that reducing the poverty rate to 1% (from a baseline of 12% at the time of last survey) would cost $170B nominal per year. This is 5.5 times the corresponding reduction in the aggregate poverty gap, but only 19% of the cost of universal basic income. Extrapolated globally, the results correspond to a cost of (approximately) ending extreme poverty of roughly 0.3% of global GDP.
Measuring Religion from Behavior: Violence, Economic Shocks and Religious Adherence in Afghanistan - joint with Oeindrila Dube and Michael Callen (Accepted, Journal of Political Economy)
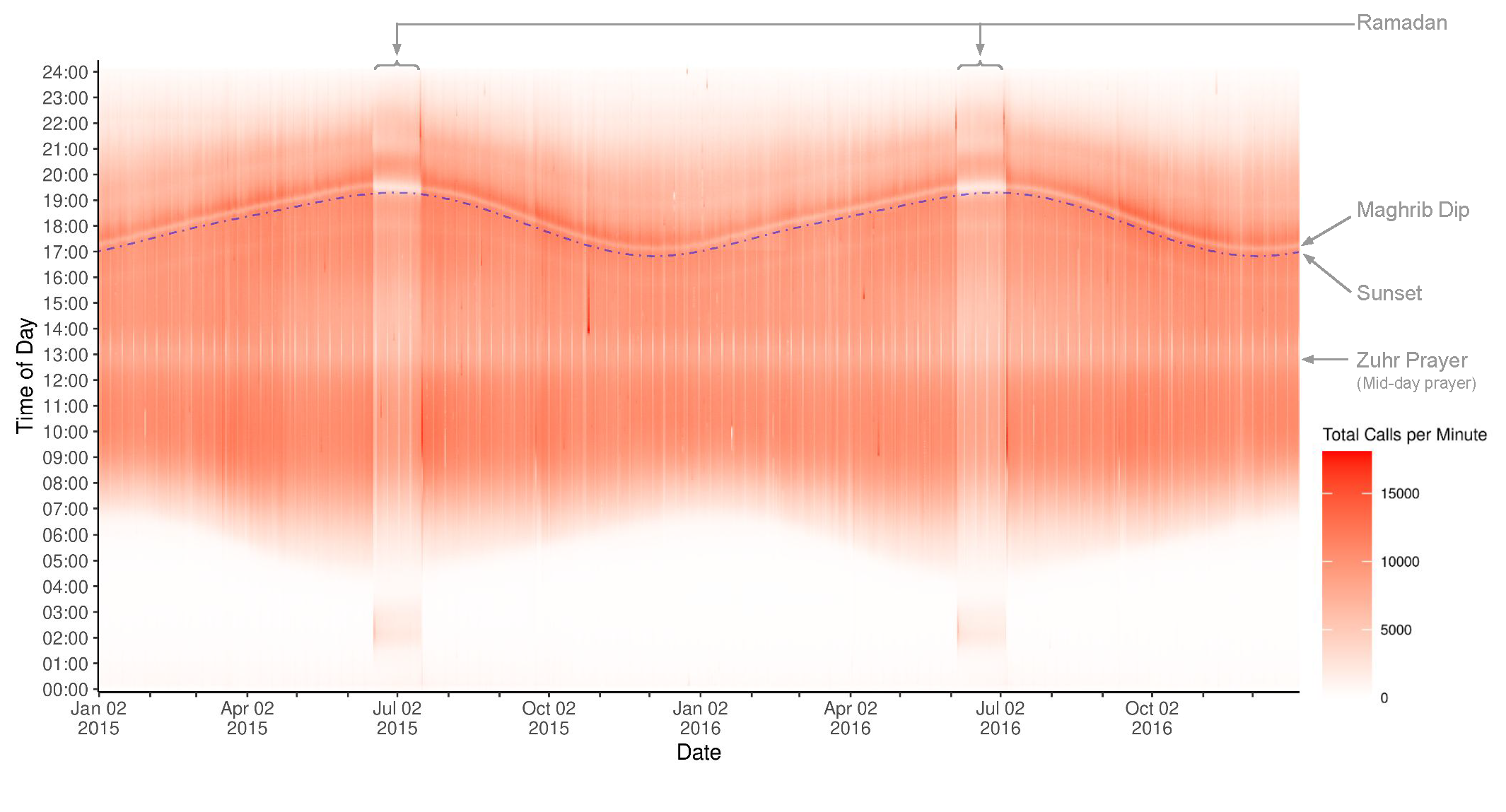
Religion plays a fundamental role in society but is often difficult to measure. We develop a novel method for measuring religious adherence that is based on decreases in digital activity during periods set aside for prayer. We apply this approach to a dataset of roughly 23 billion phone calls to study the determinants of religious practice in Afghanistan. We find that religious adherence declines after violent attacks by Islamist insurgents but increases in response to droughts in agricultural regions. This approach creates new avenues for studying religious behavior in contexts where conventional data are unavailable or unreliable.
Scalable Targeting of Social Protection: When Do Algorithms Out-Perform Surveys and Community Knowledge? - joint with Emily Aiken, Anik Ashraf, Raymond Guiteras, Mushfiq Mobarak

Innovations in big data and algorithms are enabling new approaches to target interventions at scale. We compare the accuracy of three different systems for identifying the poor to receive benefit transfers --- proxy means-testing, nominations from community members, and an algorithmic approach using machine learning to predict poverty using mobile phone usage behavior --- and study how their cost-effectiveness varies with the scale and scope of the program. While proxy-means testing is most accurate, algorithmic targeting becomes more cost-effective for national-scale programs where large numbers of households have to be screened.
Strengthening Fragile States: Evidence from Mobile Salary Payments in Afghanistan - joint with Michael Callen, Anastasia Faikina, Stefano Fiorin, Tarek Ghani (Accepted, Review of Economic Studies)
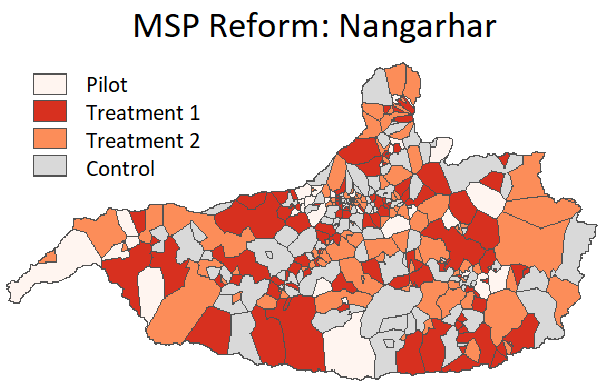
We conduct a randomized evaluation of a flagship Afghan government initiative aimed at building state administrative capacity during a period when the state faced existential uncertainty. The program aimed to modernize employee tracking and salary payments in the Ministry of Education through biometric registration and digital payment systems. The reform reduced payment delays, decreased teacher turnover, modestly improved student learning outcomes, and expanded financial inclusion. Employee enrollment was higher in districts where citizens had greater confidence in and consensus about the government’s prospects to defeat the Taliban.
Insecurity and Firm Displacement: Evidence from Afghan Corporate Phone Records - joint with Tarek Ghani, Sylvan Herskowitz, Ethan B. Kapstein, Thomas Scherer, and Ott Toomet (Accepted, American Economic Journal: Economic Policy)
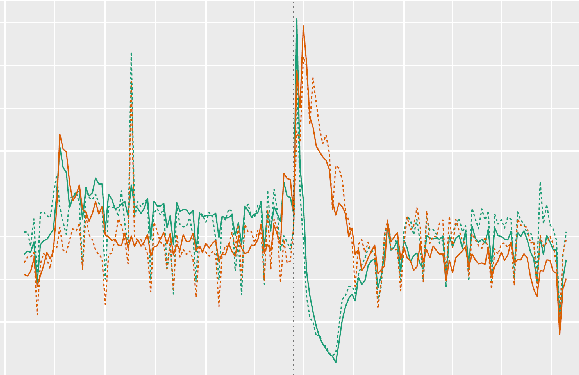
We provide new evidence on how insecurity affects firm behavior by linking data on violent conflict in Afghanistan to geo-stamped corporate mobile phone records. We begin by developing a method for observing firm location choice with phone data, and validate these measurements using independent sources of administrative and survey data. Next, we show that deadly terrorist attacks reduce the presence of firms in targeted districts by 4-6%. The effect includes both an increase in the local exit of existing firms following attacks and a decrease in new firm entry. We find large negative spillovers from attacks in provincial capitals on firm presence in nearby rural districts. After violence, employees in provincial capitals are 33% more likely to move to Kabul and 15% more likely to leave for another province.

Many decisions that once were made by humans are now made using algorithms. These algorithms are typically designed with a single, profit-related objective in mind: Loan approval algorithms are designed to maximize profit, smart phone apps are optimized for engagement, and news feeds are optimized for clicks. However, these decisions have side effects: irresponsible payday loans, addictive apps, and fake news can harm individuals and society. This project develops and tests a new paradigm for prioritizing the social impact of an algorithmic decision from the start, rather than as an afterthought. The key insight is to leverage recent advances in machine learning -- which make it possible to predict who will benefit from a decision and how -- to design algorithms that balance those predicted benefits alongside traditional profit-related objectives.
The Impact of Mobile Phones: Experimental Evidence from the Random Assignment of New Cell Towers - joint with Niall Keleher, Arman Rezaee, Erin Troland

We present experimental evidence on the economic impacts of access to a mobile phone network. We randomly assigned 14 isolated and previously unconnected villages in the Philippines to either receive or not receive a new mobile phone tower. Detailed social network surveys indicate that access to the phone network increased the number and strength of social connections within and between communities. Mobile phone networks significantly increased household income, expenditures, and food security. These impacts were driven primarily by an increase in migration, remittances, and self-employment income. We do not find significant effects on market access, informedness, or subjective well being.